Objective-C has been the foundational language of the iOS ecosystem, serving as the primary language for building applications on Apple’s mobile platform. But times have changed. In our study [1] of 84,000 unique iOS apps collected over five years (2020-2025), we found that today’s App Store hosts a rich variety of programming languages. Modern iOS apps frequently combine multiple languages such as Swift, Objective-C, C++, JavaScript, C#, Dart (Flutter), and Kotlin. This growing diversity has direct implications for security analysis.

Automated security scanners rely on dataflow analysis to trace whether sensitive user data like location, contacts, or health records could be leaked to unintended destinations, sent over the network, or collected by tracking libraries. These analyses must understand the specific binary constructs each language produces, and they can only protect what they can parse. As the language landscape of iOS grows more diverse, keeping track of which languages are actually in use becomes essential for building tools that can keep up. In our ongoing research project XDaFlowD, we are actively developing tools to address this gap by building analysis capabilities that can handle the multi-language reality of today’s iOS ecosystem.
Language Traces in App Packages
An iOS app is distributed in the ipa format, which is essentially a zip archive containing configuration data, executable binaries in Apple’s Mach-O format, and various resources such as images or web content. Programming languages leave traces in the metadata that surrounds the executable code. Our goal was to perform a fast language analysis, so we focused on easily accessible language traces within the binary. Further details on our methodology can be found in [1].
Four Languages in Every App
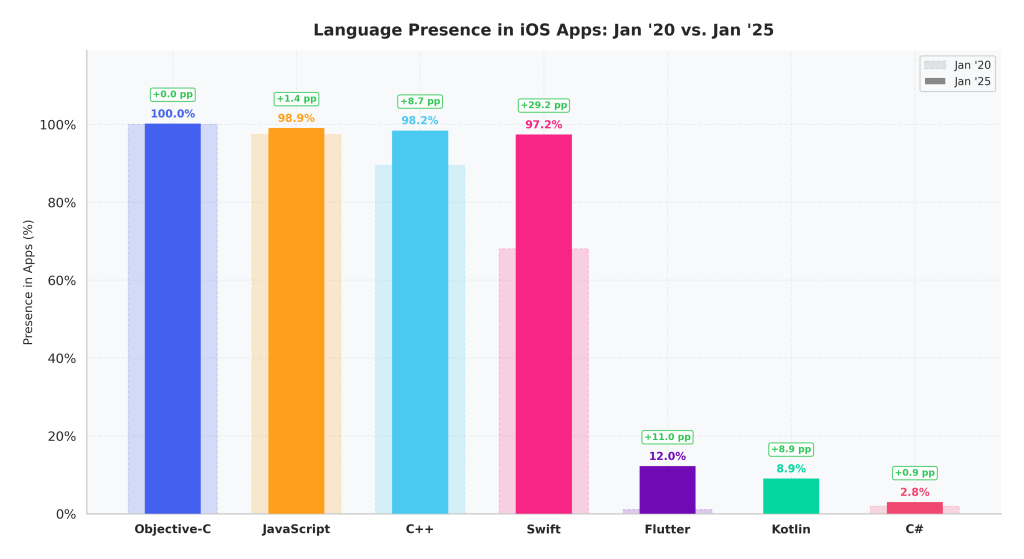
We tracked the 2,000 most popular free apps in the iOS App Store monthly over five years, covering more than 84,000 distinct apps in total. By January 2025, four languages had become nearly universal among popular apps: Objective-C, JavaScript, C++, and Swift. But this was not always the case. Swift in particular showed clear growth as Apple’s actively promoted language, rising from a presence of about two-thirds of apps in January 2020 to nearly all of them, yet without replacing Objective-C. We also observed newer cross-platform technologies gaining ground. Flutter, Kotlin, and the cross-platform framework React Native all showed notable growth. This points to an increasingly diverse iOS development landscape, where apps are built from a mix of many languages and frameworks.
New Languages, New Blind Spots
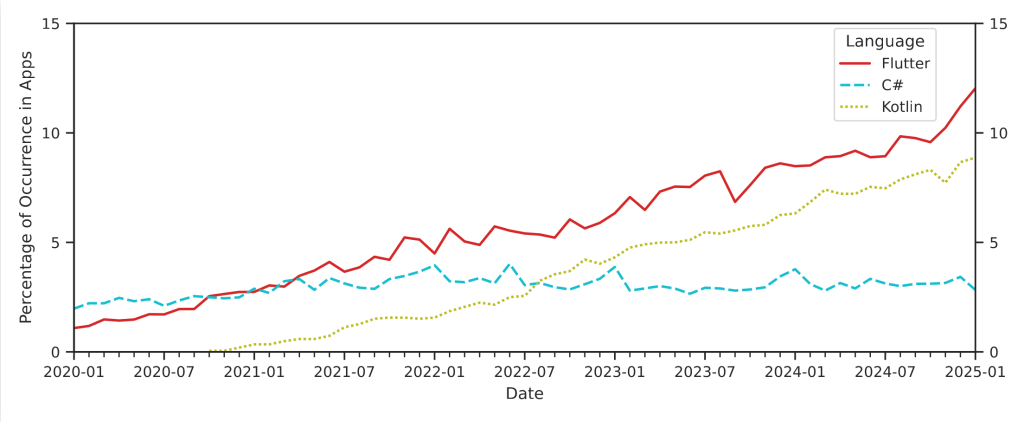
As new languages and frameworks enter the iOS ecosystem, the tools used to analyze and secure these apps do not yet fully support them. Dart, the language behind Flutter, is barely supported by existing analysis tooling. React Native compiles JavaScript into Hermes bytecode, a bytecode format that cannot even be loaded by widely used reverse engineering tools like Ghidra [2]. This means that a growing portion of the code inside popular apps is effectively invisible to current security analysis. The more diverse the development landscape becomes, the larger these blind spots grow. To address this, we are actively building new tooling to support these emerging languages and enable dataflow analysis across language boundaries, with the goal of keeping security scans of mobile iOS apps up to date with how these apps are actually built today.
References.
[1] Florian Magin, Fabian Scherf, Martin Renze, Cléo Fischer, and Gwendal Patat. 2025. Measuring While Playing Fair: An Empirical Analysis of Language and Framework Usage in the iOS App Store. In Proceedings of the 2025 Workshop on Software Understanding and Reverse Engineering (SURE ’25). Association for Computing Machinery, New York, NY, USA, 41–47. https://doi.org/10.1145/3733822.3764671
[2] National Security Agency. 2019. Ghidra Reverse Engineering Framework. Available: https://github.com/NationalSecurityAgency/ghidra